The world of Python based web applications, WSGI, its interaction with uwsgi and various deployment methods can quickly turn into a incredible array of confusingly named acronym soup. If you jump straight into the uwsgi documentation it is almost certain you will get lost before you start!
Below tries to lay out a primer for the foundations of application deployment within devstack; a tool for creating a self-contained OpenStack environment for testing and interactive development. However, it is hopefully of more general interest for those new to some of these concepts too.
WSGI
Let's start with WSGI. Fully described in PEP 333 -- Python Web Server Gateway Interface the core concept a standardised way for a Python program to be called in response to a web request. In essence, it bundles the parameters from the incoming request into known objects, and gives you can object to put data into that will get back to the requesting client. The "simplest application", taken from the PEP directly below, highlights this perfectly:
def simple_app(environ, start_response):
"""Simplest possible application object"""
status = '200 OK'
response_headers = [('Content-type', 'text/plain')]
start_response(status, response_headers)
return ['Hello world!\n']
You can start building frameworks on top of this, but yet maintain broad interoperability as you build your application. There is plenty more to it, but that's all you need to follow for now.
Using WSGI
Your WSGI based application needs to get a request from somewhere. We'll refer to the diagram below for discussions of how WSGI based applications can be deployed.
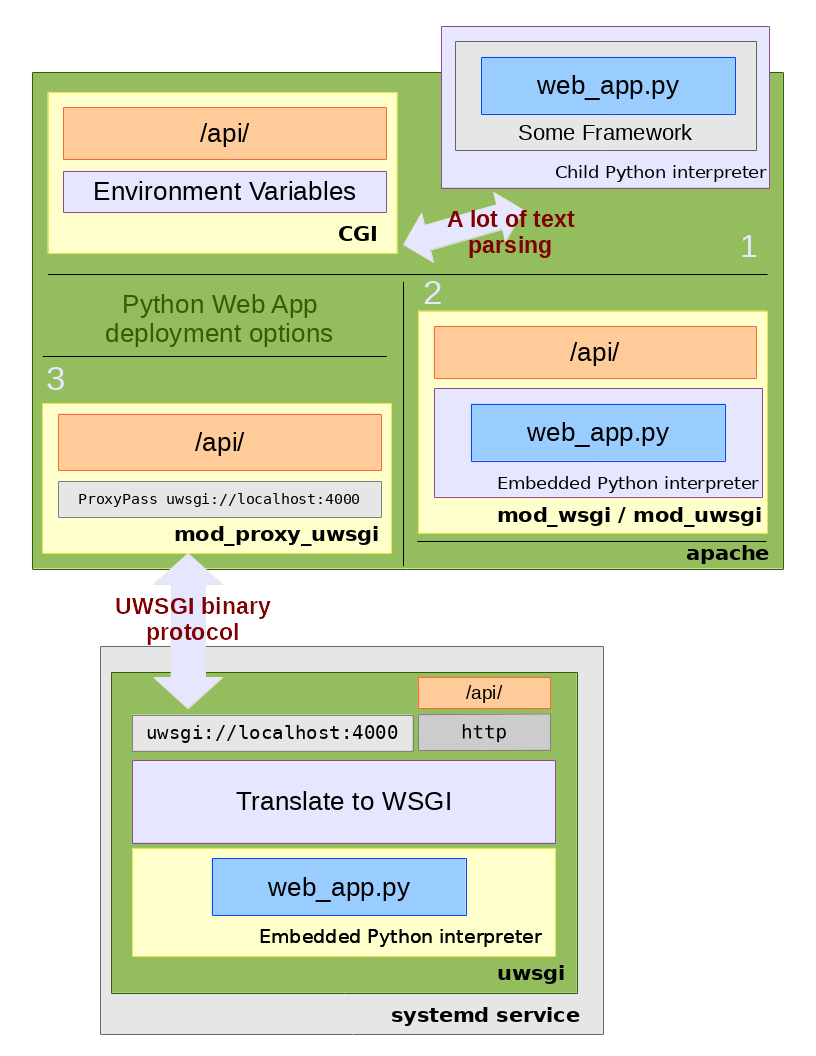
In general, this is illustrating how an API end-point http://service.com/api/ might be connected together to an underlying WSGI implementation written in Python (web_app.py). Of course, there are going to be layers and frameworks and libraries and heavens knows what else in any real deployment. We're just concentrating on Apache integration -- the client request hits Apache first and then gets handled as described below.
CGI
Starting with 1 in the diagram above, we see CGI or "Common Gateway Interface". This is the oldest and most generic method of a web server calling an external application in response to an incoming request. The details of the request are put into environment variables and whatever process is configured to respond to that URL is fork() -ed. In essence, whatever comes back from stdout is sent back to the client and then the process is killed. The next request comes in and it starts all over again.
This can certainly be done with WSGI; above we illustrate that you'd have a framework layer that would translate the environment variables into the python environ object and connect up the processes output to gather the response.
The advantage of CGI is that it is the lowest common denominator of "call this when a request comes in". It works with anything you can exec, from shell scripts to compiled binaries. However, forking processes is expensive, and parsing the environment variables involves a lot of fiddly string processing. These become issues as you scale.
Modules
Illustrated by 2 above, it is possible to embed a Python interpreter directly into the web server and call the application from there. This is broadly how mod_python, mod_wsgi and mod_uwsgi all work.
The overheads of marshaling arguments into strings via environment variables, then unmarshaling them back to Python objects can be removed in this model. The web server handles the tricky parts of communicating with the remote client, and the module "just" needs to translate the internal structures of the request and response into the Python WSGI representation. The web server can manage the response handlers directly leading to further opportunities for performance optimisations (more persistent state, etc.).
The problem with this model is that your web server becomes part of your application. This may sound a bit silly -- of course if the web server doesn't take client requests nothing works. However, there are several situations where (as usual in computer science) a layer of abstraction can be of benefit. Being part of the web server means you have to write to its APIs and, in general, its view of the world. For example, mod_uwsgi documentation says
"This is the original module. It is solid, but incredibly ugly and does not follow a lot of apache coding convention style".
mod_python is deprecated with mod_wsgi as the replacement. These are obviously tied very closely to internal Apache concepts.
In production environments, you need things like load-balancing, high-availability and caching that all need to integrate into this model. Thus you will have to additionally ensure these various layers all integrate directly with your web server.
Since your application is the web server, any time you make small changes you essentially need to manage the whole web server; often with a complete restart. Devstack is a great example of this; where you have 5-6 different WSGI-based services running to simulate your OpenStack environment (compute service, network service, image service, block storage, etc) but you are only working on one component which you wish to iterate quickly on. Stopping everything to update one component can be tricky in both production and development.
uwsgi
Which brings us to uwsgi (I call this "micro-wsgi" but I don't know if it actually intended to be a μ). uwsgi is a real Swiss Army knife, and can be used in contexts that don't have to do with Python or WSGI -- which I believe is why you can get quite confused if you just start looking at it in isolation.
uwsgi lets us combine some of the advantages of being part of the web server with the advantages of abstraction. uwsgi is a complete pluggable network daemon framework, but we'll just discuss it in one context illustrated by 3.
In this model, the WSGI application runs separately to the webserver within the embedded python interpreter provided by the uwsgi daemon. uwsgi is, in parts, a web-server -- as illustrated it can talk HTTP directly if you want it to, which can be exposed directly or via a traditional proxy.
By using the proxy extension mod_proxy_uwsgi we can have the advantage of being "inside" Apache and forwarding the requests via a lightweight binary channel to the application back end. In this model, uwsgi provides a uwsgi:// service using its internal protcol on a private port. The proxy module marshals the request into small packets and forwards it to the given port. uswgi takes the incoming request, quickly unmarshals it and feeds it into the WSGI application running inside. Data is sent back via similarly fast channels as the response (note you can equally use file based Unix sockets for local only communication).
Now your application has a level of abstraction to your front end. At one extreme, you could swap out Apache for some other web server completely and feed in requests just the same. Or you can have Apache start to load-balance out requests to different backend handlers transparently.
The model works very well for multiple applications living in the same name-space. For example, in the Devstack context, it's easy with mod_proxy to have Apache doing URL matching and separate out each incoming request to its appropriate back end service; e.g.
- http://service/identity gets routed to Keystone running at localhost:40000
- http://service/compute gets sent to Nova at localhost:40001
- http://service/image gets sent to glance at localhost:40002
and so on (you can see how this is exactly configured in lib/apache:write_uwsgi_config).
When a developer makes a change they simply need to restart one particular uwsgi instance with their change and the unified front-end remains untouched. In Devstack (as illustrated) the uwsgi processes are further wrapped into systemd services which facilitates easy life-cycle and log management. Of course you can imagine you start getting containers involved, then container orchestrators, then clouds-on-clouds ...
Conclusion
There's no right or wrong way to deploy complex web applications. But using an Apache front end, proxying requests via fast channels to isolated uwsgi processes running individual WSGI-based applications can provide both good performance and implementation flexibility.